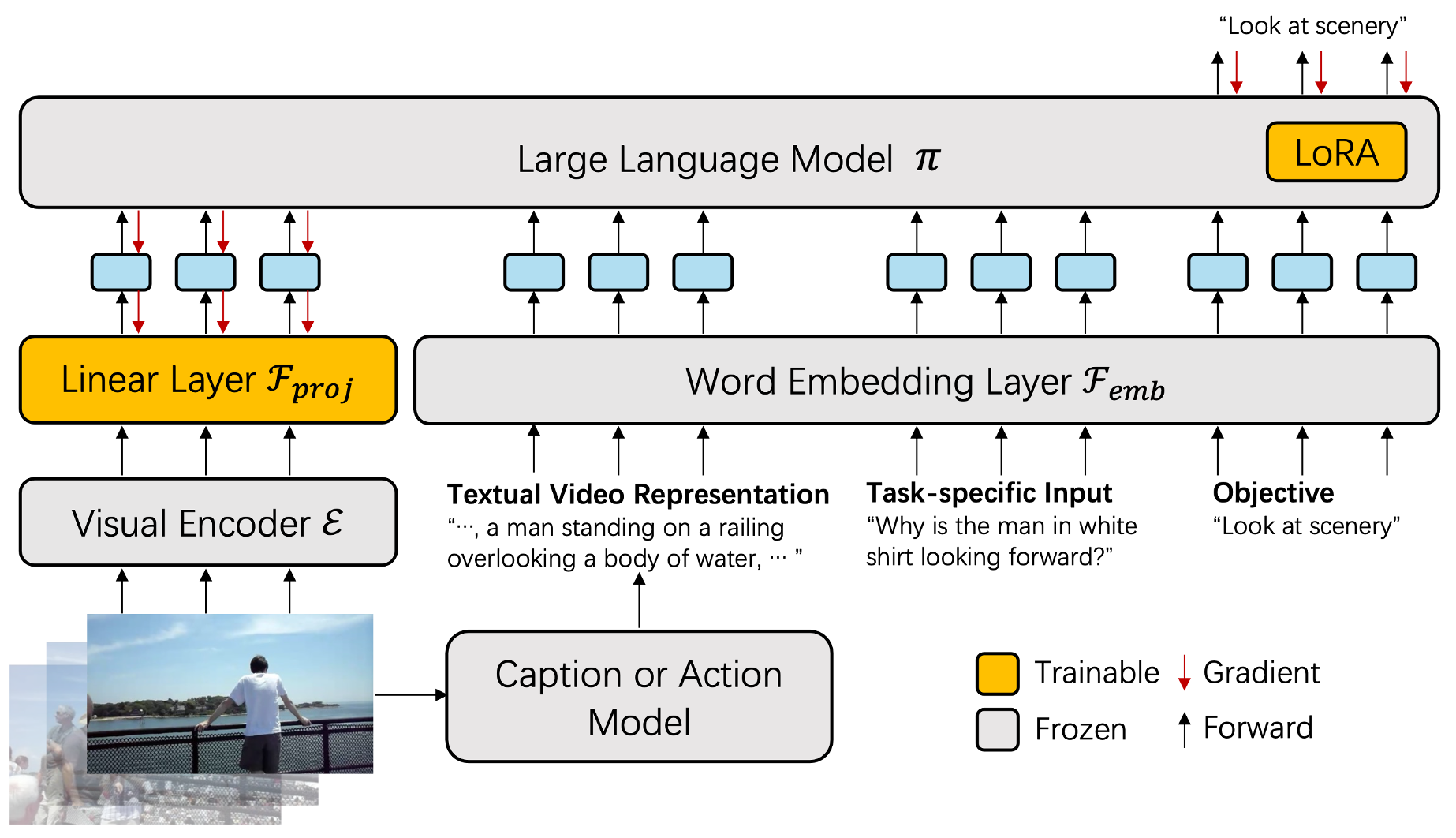
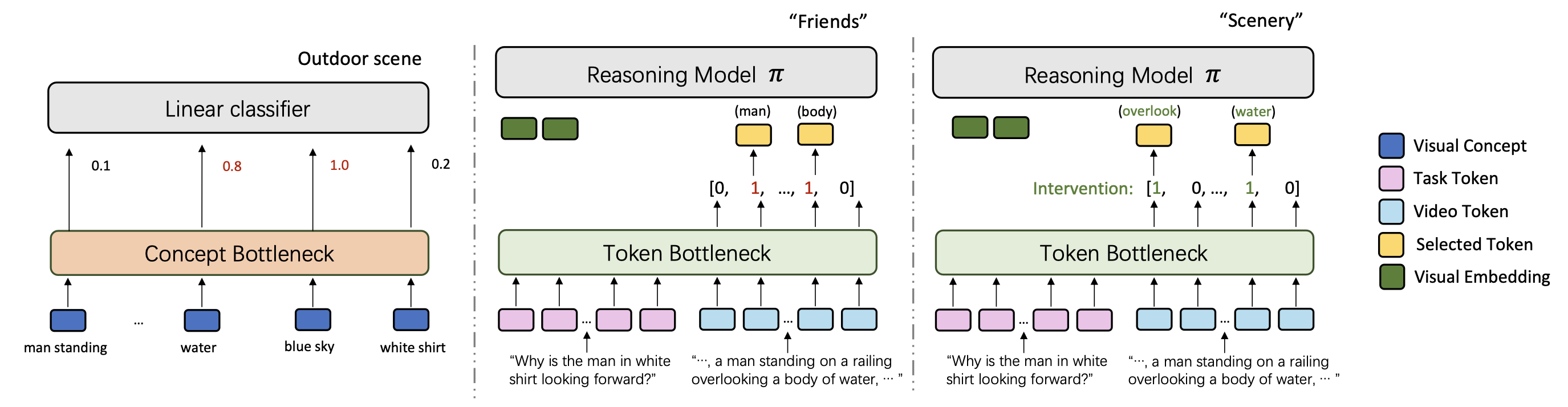
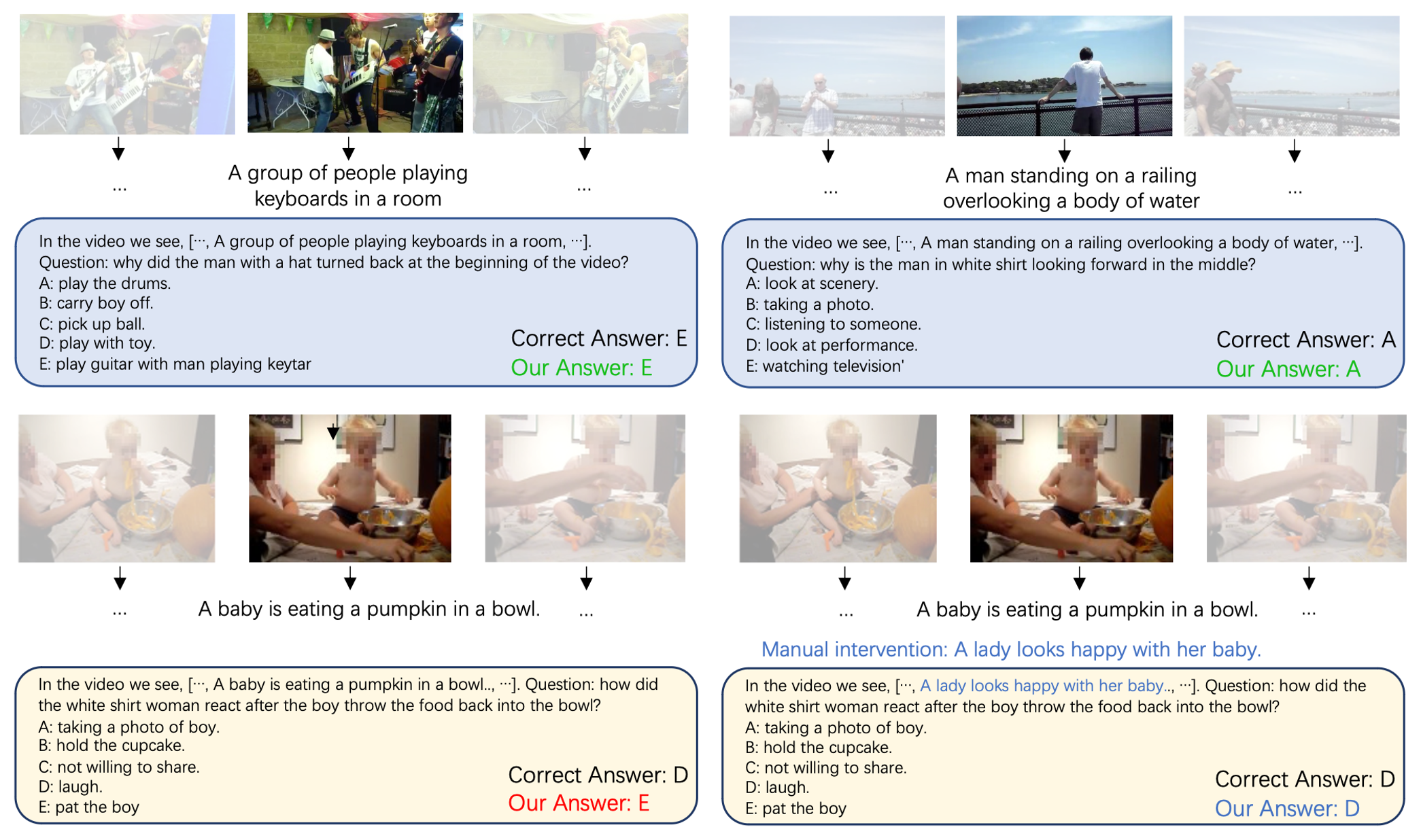
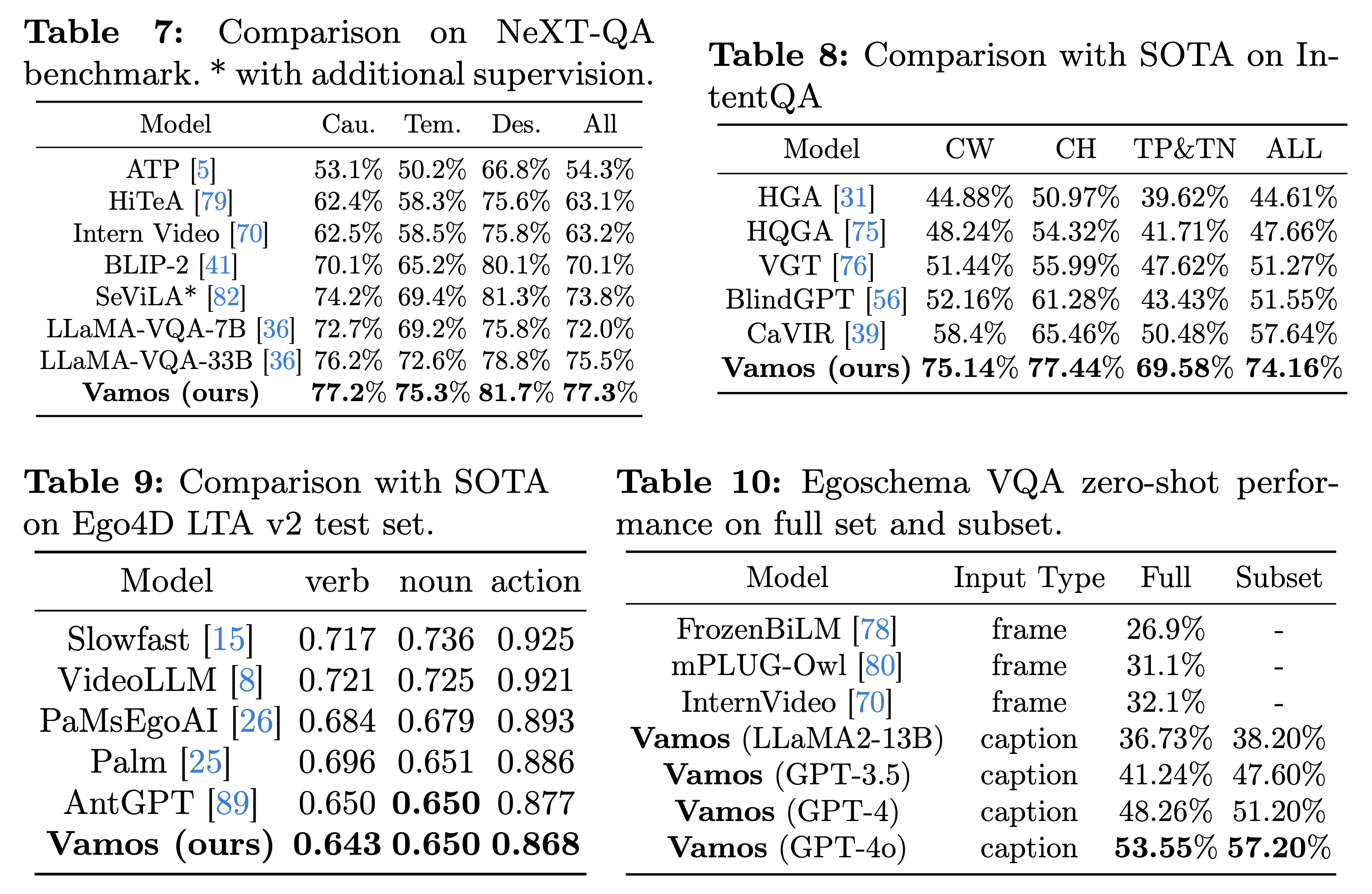
What makes good representations for video understanding, such as anticipating future activities, or answering video-conditioned questions? While earlier approaches focus on end-to-end learning directly from video pixels, we propose to revisit text-based representations, such as general-purpose video captions, which are interpretable and can be directly consumed by large language models (LLMs). Intuitively, different video understanding tasks may require representations that are complementary and at different granularity. To this end, we propose versatile action models (Vamos), a learning framework powered by a large language model as the ``reasoner'', and can flexibly leverage visual embedding and free-form text descriptions as its input. To interpret the important text evidence for question answering, we generalize the concept bottleneck model to work with tokens and nonlinear models, which uses hard attention to select a small subset of tokens from the free-form text as inputs to the LLM reasoner. We evaluate Vamos on four complementary video understanding benchmarks, Ego4D, NeXT-QA, IntentQA, and EgoSchema, on its capability to model temporal dynamics, encode visual history, and perform reasoning. Surprisingly, we observe that text-based representations consistently achieve competitive performance on all benchmarks, and that visual embeddings provide marginal or no performance improvement, demonstrating the effectiveness of text-based video representation in the LLM era. We also demonstrate that our token bottleneck model is able to select relevant evidence from free-form text, support test-time intervention, and achieves nearly 5 times inference speedup while keeping a competitive question answering performance.