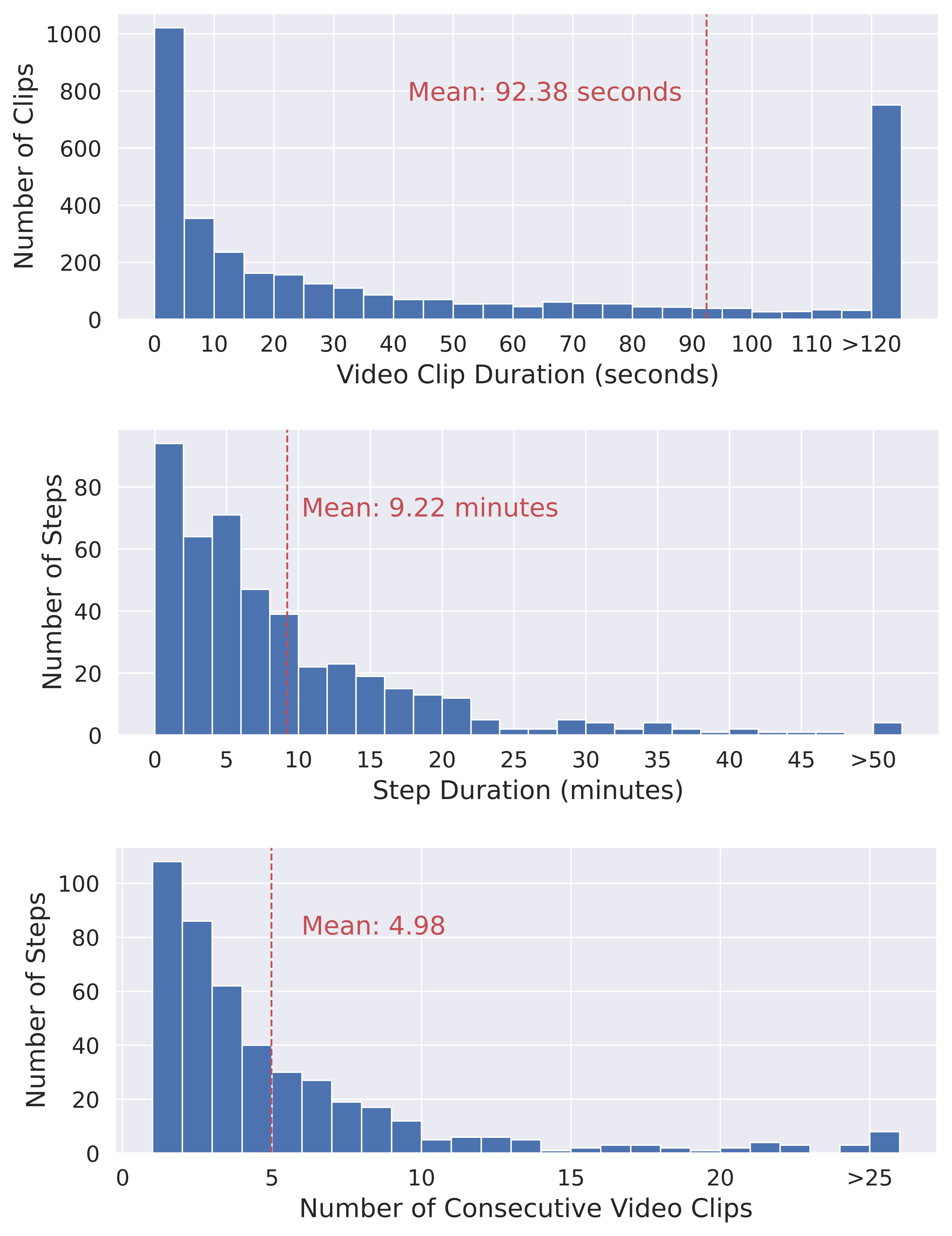
Spacewalk-18 Dataset

In spacewalk missions, astronauts leave the space station to perform various tasks (e.g., equipment repairs). While each spacewalk mission often lasts a few hours, it follows a fairly rigid agenda, which is reviewed step by step in a short animated video. In Spacewalk-18, we collected 18 spacewalk recordings from the web. As illustrated above, the steps in spacewalk mission are manually localized in the videos. In the following video, we showcase a few annotated steps, each including its animation and several corresponding clips from the spacewalk videos.