
Abstract
Can we better anticipate an actor's future actions (e.g. mix eggs) by knowing what commonly
happens after the current action (e.g. crack eggs)? What if the actor also shares the goal
(e.g. make fried rice) with us? The long-term action anticipation (LTA) task aims to predict
an actor's future behavior from video observations in the form of verb and noun sequences, and it
is crucial for human-machine interaction. We propose to formulate the LTA task from two perspectives:
a bottom-up approach that predicts the next actions autoregressively by modeling temporal dynamics;
and a top-down approach that infers the goal of the actor and plans the needed procedure
to accomplish the goal. We hypothesize that large language models (LLMs), which have been pretrained
on procedure text data (e.g. recipes, how-tos), have the potential to help LTA from both perspectives.
It can help provide the prior knowledge on the possible next actions, and infer the goal given the observed
part of a procedure, respectively. We propose AntGPT, which represents video observations
as sequences
of human actions, and uses the action representation for an LLM to infer the goals and model temporal
dynamics.
AntGPT achieves state-of-the-art performance on Ego4D LTA v1 and v2, EPIC-Kitchens-55, as
well
as EGTEA GAZE+, thanks to LLMs' goal inference and temporal dynamics modeling capabilities. We further
demonstrate that these capabilities can be effectively distilled into a compact neural network 1.3% of
the original LLM model size.
AntGPT and its novel capabilities
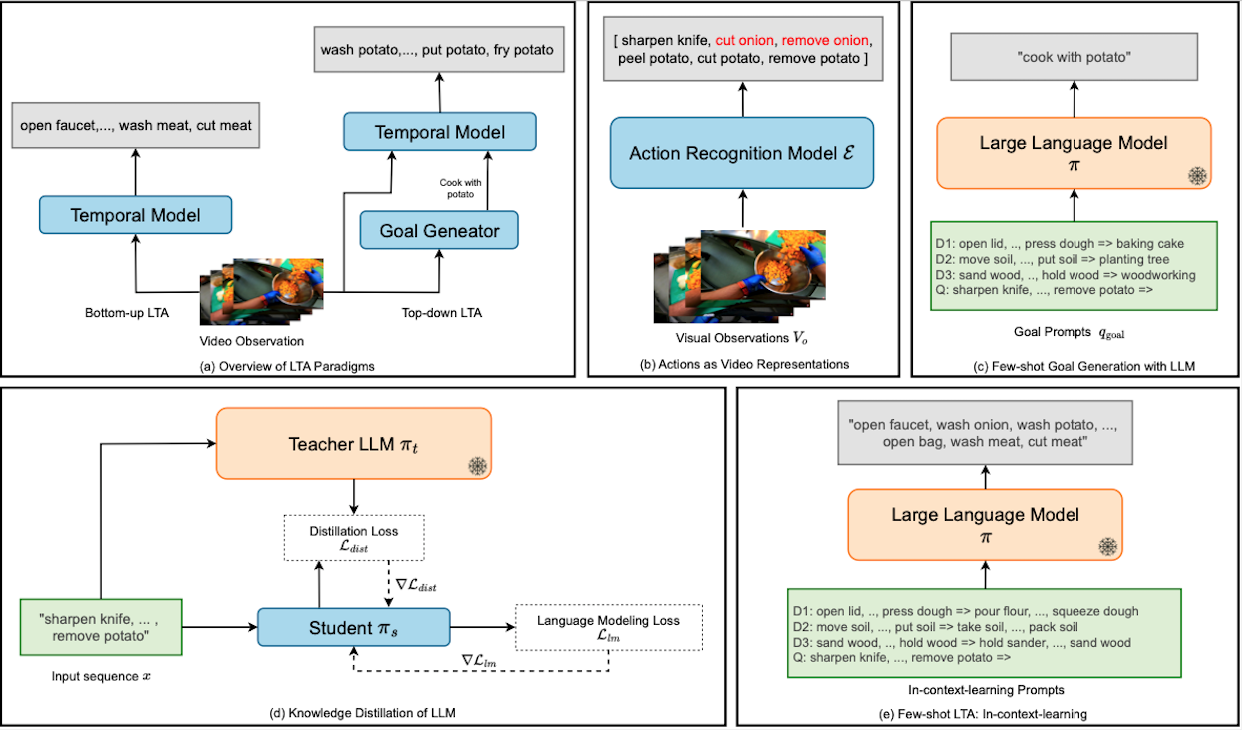 A illustration of how AntGPT utilize language models for LTA.
A illustration of how AntGPT utilize language models for LTA.
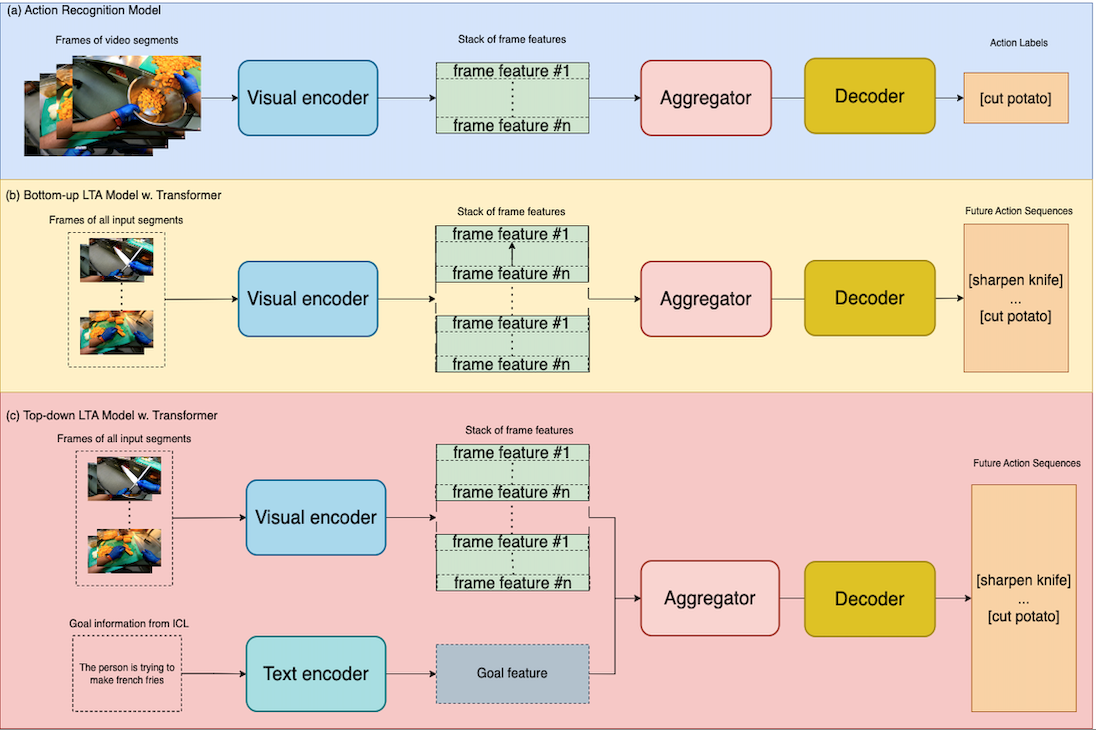 An illustration of AntGPT's top-down framework.
An illustration of AntGPT's top-down framework.
AntGPT is a vision-language framework that aims to explore how to incorporate the emergent
capabilities of large language models into video long-term action anticipation (LTA). The LTA task is
essentially given a video observation of human actions, to anticipate what is the future actions of the
actor. To represent video information for LLMs, we use action recognition models to represent video
observations into discrete action labels. They bridge visual information and language, allowing LLMs to
perform the downstream reasoning tasks. We first query the LLM to infer the goals behind the observed
actions. Then we incorporate the goal information into a vision-only pipeline to see if such
goal-conditioned prediction is helpful. We also used LLM to directly model the temporal dynamics of human
activity to see if LLM has built-in knowledge about action priors. Last but not least, we tested the
capability of LLMs to perform the prediction tasks in a few-shot settings, using popular prompting
strategies such as "Chain-of-Thought".
AntGPT shows novel capabilities:
Predicting goals through few-shot observations: We observe that LLMs are very capable
of predicting the goals of the actor even given imperfect observed human actions. In context, we
demonstrate a few successful examples in which the correct actions and goals are given. Then in the
query, we input the observed actions sequences and let LLM output the goals.
Augmenting vision frameworks with goal information: To testify whether the output goals
are helpful for the LTA task, we encoder goal information into textual features and incorporate it into
a vision framework to perform "goal-conditioned" future prediction and observed improvement to the
state-of-the-art.
Modeling action temporal dynamics: We then explored if LLMs can directly act as a
reasoning backbone to model the temporal action dynamics. To this end, we fine-tuned LLMs on the
in-domain action sequences and observed that LLMs can bring additional improvement than a transformer
trained from-scratch.
Predicting future actions in few-shot setting: We further explored how do LLMs perform
on the LTA task in a few-shot setting. When only demonstrating a few examples in the context, LLMs can
still predict the future action sequences. Furthermore, we experimented with popular prompting
strategies.
Can LLMs Infer Goals to Assist Top-down ?
 Examples of the fine-tuned model outputs.
Examples of the fine-tuned model outputs.
 Examples of in-context learning outputs.
Examples of in-context learning outputs.
What is a good interface between videos and LLMs for the LTA task?: We experimented with
various preprocessing techniques and found that representing video segments as discrete action labels are
quite performant to interact with the LLMs, allowing LLMs to perform downstream reasoning from video
observations.
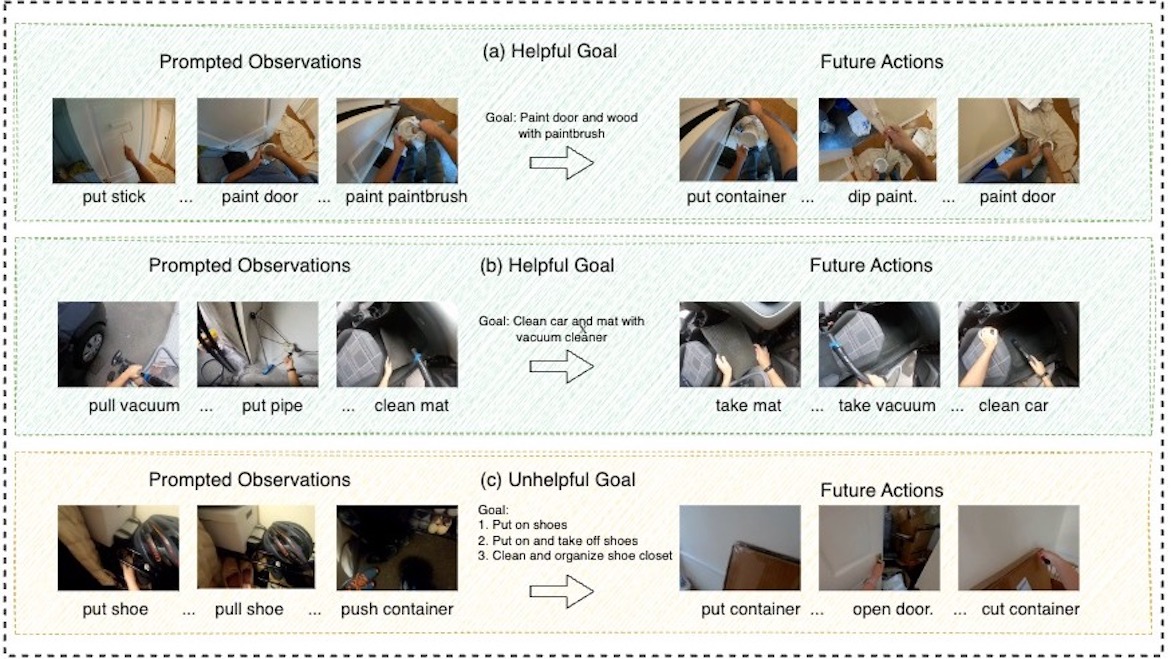
Can LLMs infer the goals and are they helpful for top-down LTA?: We find that LLMs can
infer the goals and they are particularly helpful for goal-conditioned top-down LTA. As demonstrated in our
experiment, our goal-conditioned framework consistently performs better than our vision-only frameworks.
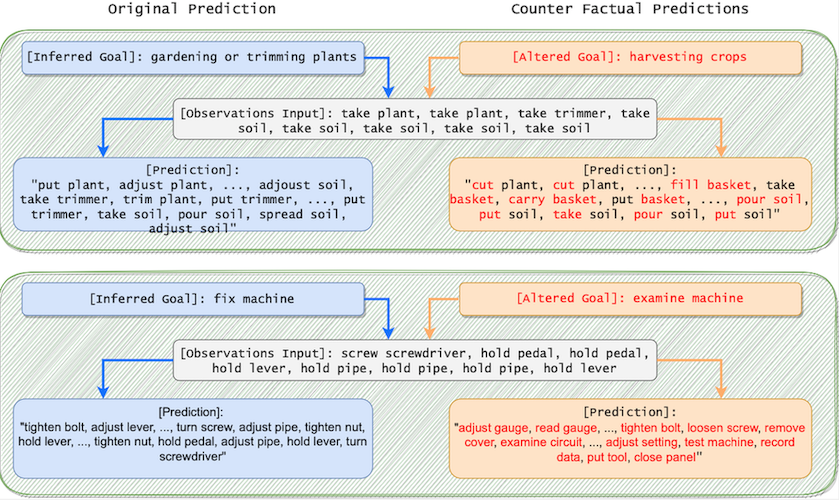
Would knowing the goals affect the action predicted by LLMs?: We did an interesting
qualitative experiment to see how about would goal affect the action prediction after we conclude goals
inferred by LLMs are useful. If we give an alternative goal instead of the truly inferred goal, how would
the output of LLM be affected? We observed that LLMs do respond according to the goal. For example, when we
switch the inferred goal "fix machines" into "examine machines", LLMs will predict some actions that are
exclusively related to "examine machines" like "read gauge", "record data", etc.
Do LLMs Model Temporal Dynamics?
 Examples of the fine-tuned model outputs.
Examples of the fine-tuned model outputs.
 Examples of in-context learning outputs.
Examples of in-context learning outputs.
LLMs are able to model temporal dynamics: We found that fine-tuned LLM are better reasoning
backbones than similar transformers trained from-scratch. Even with imperfect output structure and rough
post-processing, LLMs still outperform their transformer peers.
LLM-based temporal model performs implicit goal inference: We found that fine-tuned LLMs do
implicit goal inference as when we add inferred goal to the fine-tuned LLMs the performance does not
increase compare to their bottom-up counterparts.
Language prior encoded by LLMs benefit LTA:Through semantic perbutation experiments, we
found that with other symbolic representation of actions, the temporal dynamics modeling ability decreases
indicating that LLMs leverage the language prior to achieve better temporal dynamics modeling.
LLM-encoded knowledge can be condensed into a compact model: We conduct knowledge
distillation to train a small student model using the fine-tuned LLM as a teacher model and observed the
knowledge can be transferred and the student model can outperform the teacher model.
Few-shot predictions
 Illustration of few-shot goal inference and LTA with LLMs.
Illustration of few-shot goal inference and LTA with LLMs.
Beyond fine-tuning, we are also interested in understanding if LLM's in-context learning capability
generalizes to the LTA task. Compared with fine-tuning the model with the whole training set, in-context
learning avoids updating the weights of a pre-trained LLM.
An ICL prompt consists of three parts:
- An instruction that specifies the anticipating action task, the output format, and the verb and noun
vocabulary.
- The in-context examples randomly sampled from the training set. They are in the format of
"<observed actions> => <future actions>" with ground-truth actions.
- Finally, the query in the format
"<observed actions> => " with recognized actions.
We also attempt to leverage chain-of-thoughts prompts (CoT) to ask the LLM to first infer the goal, then
perform LTA conditioned on the inferred goal. We observe that all LLM-based methods perform much better than
the transformer baseline for few-shot LTA. Among all the LLM-based methods, top-down prediction with CoT
prompts achieves the best performance on both verb and noun. However, the gain of explicitly using goal
conditioning is marginal, similar to what we have observed when training on the full set.
BibTeX
@article{zhao2023antgpt,
title={AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos?},
author={Qi Zhao and Shijie Wang and Ce Zhang and Changcheng Fu and Minh Quan Do and Nakul Agarwal and Kwonjoon Lee and Chen Sun},
journal={ICLR},
year={2024}
}